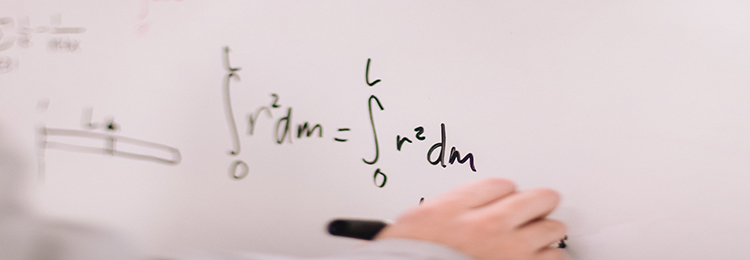
对于希望提升学术竞争力的中学生来说,参加IMMC数模竞赛是锻炼建模能力、积累团队协作经验的重要路径。但不少同学和家长最关心的问题是:零基础起步,到底有没有可能获奖?
本文不编造任何未经验证的获奖率数字,而是严格依据IMMC数模竞赛官网及中国区组委会发布的2026年官方信息,从赛制设计、评审逻辑与流程节点出发,客观分析影响拿奖概率的真实要素。
一、IMMC数模竞赛拿奖概率的底层逻辑
IMMC数模竞赛由COMAP主办,采用全球统一评审标准,奖项设置为Outstanding、Meritorious、Honorable Mention和Successful Participant四类。这种分级机制意味着:只要提交符合基本规范的建模论文,即有机会获得Successful Participant认定;而更高层级奖项则取决于建模完整性、创新性与表达质量的综合表现。
值得注意的是,赛事不设固定分数线或比例配额,评审结果基于论文本身质量而非横向排名。因此,“拿奖概率”本质上取决于团队是否达到对应奖项的实质性要求,而非参与人数或竞争比例。
关键结论:IMMC数模竞赛的获奖不是“挤独木桥”,而是“达标即获认”。能否获奖,主要取决于团队在5天连续建模周期内是否完成规范、完整、有逻辑支撑的数学建模全过程。
二、影响拿奖概率的四大关键因素
根据官方赛制说明与历年反馈,以下四个维度对最终获奖层级具有显著影响:
| 因素 | 官方依据与说明 |
|---|---|
| 团队构成 | 官方明确要求每队最多4名学生+1名指导教师。合理分工(如建模、编程、写作、协调)直接影响成果质量与时间利用效率。 |
| 时间管理 | 2026年允许团队自选连续5天完成任务。能否在有限时间内完成问题理解、假设建立、模型求解、结果验证与报告撰写,是区分Successful与更高奖项的关键。 |
| 资源运用 | 官方注明“可使用任何非生物资源”。熟练调用公开数据、数学软件与文献工具,有助于提升建模深度与表达专业性。 |
| 成果表达 | 评审标准强调“清晰性、逻辑性、合理性”。一篇结构完整、语言准确、图表规范的论文,更容易被评审识别价值,从而提升获奖层级。 |
总结来说:IMMC数模竞赛的拿奖概率并非由“运气”或“内卷程度”决定,而是与团队是否具备建模意识、协作习惯与执行能力密切相关。这些能力均可通过系统性准备得到提升。
三、2026赛季关键时间节点与备赛节奏
结合IMMC数模竞赛2026年官方赛程(2月2日–4月27日开放,论文提交于5月初自选连续5天,评审结果公布于6月底),合理安排备赛节奏能显著提高成果质量:
赛前准备期(2月–4月):
熟悉官方题型风格,掌握基础建模流程(问题重述→假设简化→模型构建→求解分析→结果检验→报告撰写)。可参考往届优秀论文学习表达范式。
实战模拟期(4月下旬):
组织1–2次全真模拟,严格限定5天周期,完整走通建模全流程。重点训练时间分配与团队协同机制。
正式参赛期(5月初):
选定连续5天启动任务,每日设定明确目标(如Day1问题分析与文献调研,Day2模型初建,Day3编程实现,Day4结果优化,Day5报告整合与润色)。留出至少半天进行交叉审阅与格式校对。
关键结论:备赛节奏越贴近真实赛制,临场发挥越稳定。把“5天建模”当作一个可拆解、可练习的过程,是提升获奖可能性的务实路径。
四、报名与组队实操指南
IMMC数模竞赛中国区提供三种报名方式,均需配备指导教师:
第一步:
学校统一报名:由指导教师在IMMC中国组委会平台注册并提交团队信息。
第二步:
官方授权机构代报:选择IMMC中国组委会认证的合作单位协助完成注册与材料提交。
第三步:
个人官网报名:访问https://www.comap.com/contests/immc-contest,按指引完成注册,须确保指导教师全程参与并完成身份确认。
总结来说:报名本身无门槛限制,但团队组建质量与指导教师参与深度,将直接影响后续建模过程的规范性与成果的专业性。这是拿奖概率的起点保障。
五、同类竞赛对比视角下的IMMC定位
相较其他国际学科竞赛,IMMC数模竞赛的独特性在于其强实践性与低知识门槛:
它不要求超纲数学知识,而更看重将现实问题转化为数学语言的能力;不依赖单人解题速度,而强调团队在有限时间内的系统性产出;不以分数论高低,而以论文质量定等级。这种设计使不同知识起点的学生,都有机会通过科学方法与有效协作获得认可。
往年获奖者中,既有数学基础扎实的学生,也有擅长逻辑表达或编程实现的同学。他们共同的特点是:在5天内完成了从问题理解到成果交付的完整闭环。
关键结论:IMMC数模竞赛的拿奖概率,与“是否学过大学数学”无关,而与“是否掌握建模思维”与“是否形成团队执行力”高度相关。
IMMC数模竞赛作为一项被麻省理工学院(MIT)等顶尖高校推荐的国际建模活动,其价值不仅体现在奖项本身,更在于过程中培养的跨学科思维、协作意识与工程化表达能力。这些素养,已在众多升学申请与学术发展中展现出持续影响力。